
OpenGL学习之路
OpenGL学习之路
前言
由于暑期实习岗位相关, 需要音视频相关的知识, 于是乎开始重新回顾大学期间学的FFmpeg的相关内容,在此期间接触到OpenGL,对其内容略感兴趣,正巧看了一个非常好的Tutorial,于是便开啃OpenGL!开工大吉!
学习研读源
注: 本博客基于LearnOpenGL-CN进行研读学习,因此许多概念及理解均从期中誊抄而来,并使用了部分图片,用于个人研读理解,不做商用。
开篇
OpenGL到底是什么?
OpenGL是一个由Khronos组织制定并维护的规范。规范规定了没哥函数该如何执行,输入输出是怎样的,但至于每个函数内部是如何实现的,将由OpenGL库的开发者执行,这通常是显卡的生产商进行的。
为什么显卡驱动需要经常升级,这也是原因之一。
历史
核心模式与立即渲染模式
早起的OpenGL使用立即渲染模式(Immediate Mode), 绘制图形很方便,但OpenGL大多数功能都被库隐藏了,也就是暴露的接口太少,灵活性太少。因此从OpenGL3.2开始,OpenGL规范鼓励开发者在其核心模式(Core-Profile)下进行开发,完全移除了旧的特性。
在使用OpenGL的核心模式时,会迫使我们使用现代函数,因此我们讲我们学习的是现代的OpenGL。但其更难学习,因为立即渲染模式中从OpenGL实际运作中抽象出了很多细节,也因此很难让人把握OpenGL是如何运作的。学习其核心模式下的开发,也会让我们更深入的理解图形编程。
因此目前我们面向OpenGL3.3的核心模式。
特性
扩展: 扩展是OpenGL的一大特性,当一个显卡公司提出一个新特性或者渲染上的优化时,通常以该方式在驱动中实现,而不必等待新的OpenGL规范。
状态机: OpenGL自身是一个巨大的状态机 📓 ,其状态通常被称为OpenGL的Context。通常使用如下途径去更改OpenGL状态:设置选项、操作缓冲,并使用上下文进行渲染。因此使用OpenGL时常会用到一些状态设置函数,来改变上下文,从而实现效果。
基于C语言: 内核是一个C库
工具与库
GLFW与GLAD
要画画,我们需要一个面板和一只画笔,那画笔这里我们使用GLFW,提供渲染物体所需的最低限度的接口并允许用户创建OpenGL上下文、创建和管理窗口。
那画板自然就是GLAD, 他是一个OpenGL函数加载器,用于获取OpenGL的API函数指针, 加载扩展以及保证版本兼容性。因为OpenGL并不是一个内置的库,而是由显卡驱动提供。而由于OpenGL驱动版本众多,大多数函数的位置都无法在编译时确定下来,需要在运行时查询,因此便有了该库。
这里我使用VsCode进行整体实验代码的编写, OpenGL的版本与Tutorial中一致, 为3.3
常规坑点-Mac下C++代码的配置问题
这里自己用的Mac好久没有使用VsCode来运行C++代码了,因此出现了一些波折。比如15.2系统无法运行C++代码,必须要升级到最新的15.3才可以,同时还需要在VsCode CodeRunner插件中添加C++11语法支持才行。一直以为系统版本对C++运行影响不大,看来还是有一些影响。
我采用的方式是比较原始的,即下载GLFW Source Code然后编译并配置到VsCode中。这一过程中也出现了一些小问题,比如在task.json中的一些编译配置的语法问题以及还有VsCode如何导入第三方库以及正确设置头文件问题。
"args": [
"-fcolor-diagnostics",
"-fansi-escape-codes",
"-g",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}",
"-I${workspaceFolder}/include",
"-L${workspaceFolder}/lib",
"-lglfw3",
// "-framework Cocoa"
"-framework", "Cocoa",
"-framework", "OpenGL",
"-framework", "IOKit"
],"-framework Cocoa" 应该改为"-framework", "Cocoa",否则会因标点符号引起编译异常。
同时自己对C++编译的符号-L -I -l -framework都不太清楚,只知道大概意思,在这里先记下来。
实践
尝试让项目跑起来
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include <iostream>
using namespace std;
void framebuffer_size_callback(GLFWwindow *window, int width, int height);
void processInput(GLFWwindow *window);
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
int main()
{
// init GLFW
glfwInit();
// GLFW setting
// specify version 3.3
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
// using core-profile
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
#ifdef __APPLE__
// especially for Mac OS X
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
#endif
// create window
GLFWwindow *window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", nullptr, nullptr);
if (window == NULL)
{
printf("Failed to create GLFW window");
glfwTerminate();
return -1;
}
// bind the window with opengl context
glfwMakeContextCurrent(window);
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
printf("Failed to initialize GLAD");
return -1;
}
// make opengl window size dynamically change with native window size changing
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
while (!glfwWindowShouldClose(window))
{
processInput(window);
// check if there is some events like input or move.
glfwPollEvents();
// switch color cache
glfwSwapBuffers(window);
}
glfwTerminate();
return 0;
}
void framebuffer_size_callback(GLFWwindow *window, int width, int height)
{
// set opengl window size (viewport)
glViewport(0, 0, width, height);
}
void processInput(GLFWwindow *window)
{
// when press, set the window should close
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
{
glfwSetWindowShouldClose(window, true);
}
}SwapBuffer-双缓冲
为什么使用双缓冲 (Double Buffer)?
首先要明确图片的绘制流畅并不是一蹴而就的,而是从左到右 从上到下每个像素地绘制。因此会导致渲染的结果不真实。
使用双缓冲能保证前一个缓冲保存着上一次最终输出的图像,在屏幕上显示,而后缓冲处理所有的渲染指令,当所有的渲染指令执行完毕后,再交换到前缓冲里,图像就能立即被呈现出来。
因此我们初步了解到OpenGL相关的重要概念:
- 窗口: OpenGL渲染窗口以及Native窗口
- OpenGL也能动态地处理输入并渲染
渲染
OpenGL将任何物体都视为处于3D空间,而屏幕和窗口是2D像素数组,因此OpenGL的大部分工作都是关于把3D坐标转化为适应屏幕的2D像素。3D坐标转2D坐标的处理过程就是由其中的图形渲染管线(Graphics Pipeline)完成的,也就是将一堆原始的图形数据途径一个输送管道,最终转化为适应屏幕的过程。其主要可分为两个部分:
- 坐标转化:将3D坐标转化为2D坐标
- 上色:将2D坐标转化为实际的有色像素
GPU中完成这些步骤的叫做着色器 (Shader)
图形渲染管线的组成与流程
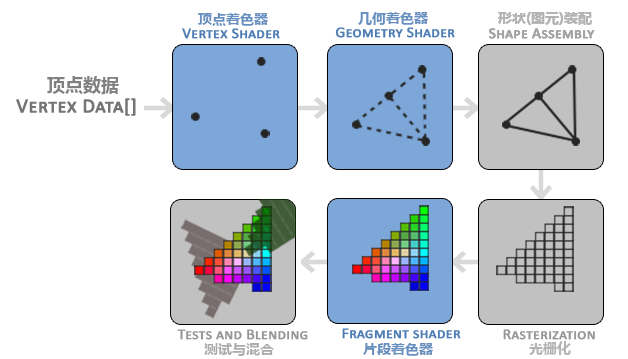
光栅化阶段:将图元映射为最终屏幕上的像素
着色器
着色器的分类
OpenGL现代渲染管线至少包含两个核心着色器(必须使用):
- 顶点着色器 Vertex Shader: 顶点变化,处理每个顶点的位置并进行顶点变化
- 片段着色器 Fragment Shader: 上色,计算每个像素低颜色,处理光照、阴影等,是OpenGL高级效果产生的地方。
还有其他着色器(可选):
- 几何着色器:生成或修改新的几何图元
- 细分控制/评估着色器
- 计算着色器
图元
在OpenGL中,数据是如何渲染的需要指定。即我们希望把数据渲染成一系列的点?还是一系列的三角形?还是一条线,这些提示被称为图元。 GL_POINTS, GL_TRIANGLES, GL_LINE_STRIP
需要注意的是,管线的渲染流程,即不同着色器的工作流程,就像工厂中的流水线一样,一条接一条。管线中,上一个着色器的输出往往作为下一个着色器的输入,因此在设置着色器时也需要考虑到顺序以及输入输出的问题。
一旦顶点坐标在顶点着色器中处理过,则它们就应该为标准化设备坐标了 (Normalized Device Coordinates, NDC)
标准化设备坐标**(Normalized Device Coordinates, NDC)**
指x、y、z都在[-1.0, 1.0]之间的坐标,需要注意(0, 0)这一点在屏幕中心,对于这类坐标,通常称为UV坐标
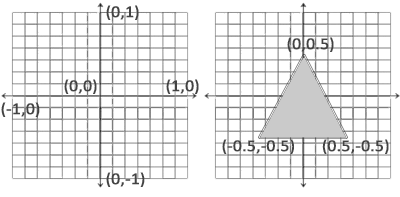
还记得glViewport这个方法吗?顶点的实际绘制位置即通过设置的size与标准化的设备坐标运算而来。
一般使用着色器的方式是:
- 基于着色器语言 GLSL(OpenGL Shading Language)编写着色器代码
- 创建Vertex Shader
- 将代码与shader对象绑定
- 运行时动态编译着色器代码
给出一段顶点着色器的初始化代码,其他着色器初始化过程类似
const char *vertexShaderSource = "#version 330 core\n"
"layout (location = 0) in vec3 aPos;\n"
"void main()\n"
"{\n"
" gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);\n"
"}\0";
GLuint vertexShader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertexShader, 1, &vertexShaderSource, nullptr);
glCompileShader(vertexShader);
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(vertexShader, 512, nullptr, infoLog);
printf("Error in compiling shader, %s", infoLog);
}对于顶点着色器,一次仅处理一个顶点,而对于片段着色器,一次处理一个像素
缓冲对象
VBO & VAO & EBO
顶点数组对象VBO(Vertex Array Object): VBO是GPU显存中的一块区域, 用于存储顶点数据。
顶点缓冲对象VAO(Vertex Buffer Object):VAO是一个记录VBO数据格式的对象,告诉OpenGL如何解析VBO的数据。
VBO VAO是相辅相成的,VBO存储了实际的顶点数据,而VAO为OpenGL指示了如何使用VBO中的数据。
Why VBO/VAO?
VBO
在OpenGL立即渲染模式中,顶点数据存储在CPU内存中,每次渲染时数据都从CPU发送到GPU,十分缓慢(猜测与CPU-GPU的总线有关系?)
而VBO直接将数据存在GPU中,不经过CPU,渲染快。并且VBO能一次性上传多个数据,而传统方式只能逐个提交顶点。
VAO
如果不使用VAO, 则每次绘制前必须手动绑定gVBO并设置glVertexAttribPointer来告诉OpenGL该如何使用VBO数据,效率低并且大量的OpenGL API调用 降低性能。
使用VAO后,只需要设置一次,后续绘制时绑定VAO,即可从VAO中取出指示数据
常规的VBO VAO绑定流程
static float vertices[] = {
-0.5f, -0.5f, 0.0f, // left
0.5f, -0.5f, 0.0f, // right
0.0f, 0.5f, 0.0f // top
};
GLuint VBO, VAO;
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void *)0);
glEnableVertexAttribArray(0);EBO
元素缓冲对象Element Buffer Object,又名索引缓冲对象Index Buffer Object,核心是节约内存
Why EBO?
考虑一个问题,如果我们想要绘制一个矩形该怎么做呢?我们知道OpenGL的绘制最多是一个三角形,所以需要两个三角形组成矩形,那绘制两个三角形按照之前的方式要怎么做呢?
我们会定义两套表示各自图形的顶点,就三角形而言,则需要六个顶点。但其实可能存在顶点重复现象,比如以下
float vertices[] = {
// 第一个三角形
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, 0.5f, 0.0f, // 左上角
// 第二个三角形
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};这就产生了空间上的浪费,有没有索引的方式来表示顶点呢?类似JVM中的String Table?
这就是EBO的作用,它存储了OpenGL用来绘制的顶点的索引,我们只需要在VBO中定义不相同的四个顶点数据,然后在EBO中声明其索引值即可。只是需要注意EBO的初始化以及绑定方式、渲染方法与VBO有不同
疑惑解答
关于VBO & VBO & EBO,在实践上自己还有一些总结,这里统一列出
- VAO、VBO、EBO不需要反复的解绑与绑定,只有可能在特定条件下才解绑
- 可以使用多个VAO来渲染
- 多个program可以参与一个窗口的绘制
GLSL
GLSL是一种类C语言,专门为着色器而构造。
一个常规的着色器有以下结构
#version version_number
in type in_variable_name;
in type in_variable_name;
out type out_variable_name;
uniform type uniform_name;
void main()
{
// 处理输入并进行一些图形操作
...
// 输出处理过的结果到输出变量
out_variable_name = weird_stuff_we_processed;
}需要注意#version 并不是注释,而是声明其版本,并且需要注意,输入、输出变量也需要提前声明。输入变量可声明数是有限的,一般是16个包含4分量的顶点属性可用(感觉这可能跟GPU或CPU里的寄存器数量有关?)。
数据类型
基本数据类型:int、float、double、uint、bool
向量:可以包含有2、3、4个分量的容器,这也使得其可以表示颜色(RGBA)
| 类型 | 含义 |
|---|---|
vecn | 包含n个float分量的默认向量 |
bvecn | 包含n个bool分量的向量 |
ivecn | 包含n个int分量的向量 |
uvecn | 包含n个unsigned int分量的向量 |
dvecn | 包含n个double分量的向量 |
获取一个向量的分量用vec.x .y .z .w
向量的创建与重组
vec2 vect = vec2(0.5, 0.7);
vec3 vecT = vec3(vec2, 0.2);也可以用 vec4 newVec = oldVec.xyxx 这种方式来进行分量选择与创建
输入与输出
为什么使用in out关键字?方便不同着色器连接到Program时,Program检查其输入输出的匹配性。
因此我们在着色器之间发送数据时,要确保后一个的输入是前一个的输出。
例外
但顶点着色器作为管线渲染的开头,其应该接受的是一种特殊形式的输入,否则会效率低下,因为它从顶点数据中直接接受输入。为了定义顶点数据该如何管理,我们用location来指定输入变量,这样才可以在CPU上配置顶点属性。因此在这之前定义顶点着色器时,我们需要使用layout (location = 0)
layout (location = 0) in vec3 aPos;含义:
可以理解为从VBO中索引为0的位置取一个数据类型为vec3的数据作为输入变量aPos
同时对于顶点着色器,指定变换后的顶点位置不需要额外设置输出变量,只需要赋值到gl_Position即可
片段着色器也是个例外,因为其需要一个vec4颜色输出变量,因为片段着色器最终需要生成一个颜色。
提示
你也可以忽略layout (location = 0)标识符,通过在OpenGL代码中使用glGetAttribLocation查询属性位置值(Location),但是我更喜欢在着色器中设置它们,这样会更容易理解而且节省你(和OpenGL)的工作量。
相连着色器中输入输出变量名一致性
需要明确的是,在两个首尾相接的着色器中,前一个的输出变量名必须与后一个输出变量名匹配(完全一致),着色器并不是根据out/in变量声明位置来进行输入输出匹配,而是根据变量名匹配,所以需要注意一致性问题。
一个例子来理解location指定的输入 & glVertexAttribPointer(int) & VBO结构
试想下如何为每个顶点设置不同的颜色参数?并传递给FragmentShader?
看起来的思路是定义在VBO中 由Vertex Shader读取并传递给Fragment Shader?可以尝试下该怎么做。
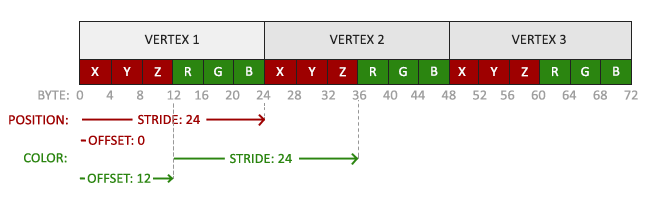
VBO中假设数据是这样的
float vertices[] = {
// 位置 // 颜色
0.5f, -0.5f, 0.0f, 1.0f, 0.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, // 左下
0.0f, 0.5f, 0.0f, 0.0f, 0.0f, 1.0f // 顶部
};
Vertex Shader中的代码可能是这样
#version 330 core
layout (location = 0) in vec3 aPos; // 位置变量的属性位置值为 0
layout (location = 1) in vec3 aColor; // 颜色变量的属性位置值为 1
out vec3 ourColor; // 向片段着色器输出一个颜色
void main()
{
gl_Position = vec4(aPos, 1.0);
ourColor = aColor; // 将ourColor设置为我们从顶点数据那里得到的输入颜色
}在VBO绑定与定义时,会如下向OpenGL指示:
// 位置属性
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 颜色属性
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)(3* sizeof(float)));
glEnableVertexAttribArray(1);即我们告诉OpenGL(结合上面的结构图来理解):
- location为0的输入,其类型为Float,占3个字节大小,下一个location0的输入在6个字节后(可理解为组间隙),偏移地址为0.
- location为0的输入,其类型为Float,占3个字节大小,下一个location1的输入在6个字节后(可理解为组间隙),偏移地址为3(因为前三个字节为location0).
最终使用glEnableVertexAttribArray(int)来告诉OpenGL启用location为0 和 1的顶点属性
但不觉得有点问题吗?上面的例子我们只是指定了每个顶点的色值,那最后怎么又以**填充(Fill)**的形式绘制出来呢?之前我们在Fragment Shader中设置的值是固定的,似乎还可以理解,但现在变成不同的色值了,那该怎么理解呢?
实际的图片其实是这样
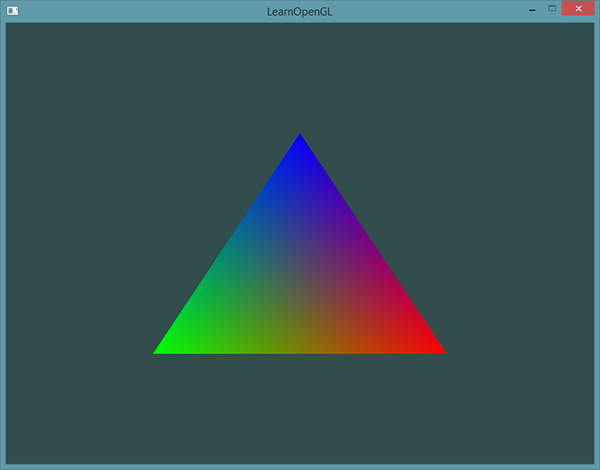
为什么会有这样的结果?我们只是提供了三种颜色呀。
这就是Fragment Shader中所进行片段插值的结果,请回顾一下核心模式下管线渲染的流程。光栅化在片段着色器之前,当流程当渲染一个三角形时,光栅化阶段通常会造成比原来指定顶点更多的片段,光栅会根据每个片段在三角形形状上所出相对位置决定这些片段的位置,基于这些位置,它会插值所有片段着色器的输入变量,在有明确指定颜色的两个顶点间进行颜色的线性结合。片段插值会被应用到片段着色器的所有输入属性上。
Uniform
Uniform是另一种在CPU上传递数据到GPU着色器的方式。
Uniform是全局的,因此每个变量命名必须在所有的着色器中独一无二的,他可以被着色器程序的任意着色器在任意阶段访问。并且uniform的值一旦声明就会一直保存直到下次更改。
动态修改
这就带来了Uniform的一大好处,就是可以在渲染期间动态修改变量,来达到动画的效果
不过需要注意的是,我们需要通过glGetUniformLocation来获取该uniform变量在内存中的实际位置并通过glUniformNX来改变其值
纹理
纹理 Texture,是一种用于给物体表面添加细节的技术(颜色、图案、光照),类似于纹理是一层皮,贴到物体的表面,让物体看起来更加真实。
如果没有纹理又想让物体看起来真实,那就需要指定足够多的顶点与足够多的颜色,这会产生很多额外开销。
为了将纹理映射到图案上,我们需要指定图案中顶点对应纹理的具体部分,因此每个顶点就关联了一个纹理坐标(Texture Coordinate),这是一个二维坐标,从(0, 0) -> (1, 1)的值。来指明该从纹理图像的哪个部分采样。(采样 Sampling即为基于纹理坐标获取纹理颜色)。之后再图形的其他片段上进行片段插值。
插值也有不同的插值方式,因此我们需要告诉OpenGL如何对纹理采样
环绕方式
纹理坐标范围是(0, 0) -> (1, 1), 但如果超出这个值域外,有不同的环绕方式
| 环绕方式 | 描述 |
|---|---|
| GL_REPEAT | 对纹理的默认行为。重复纹理图像。 |
| GL_MIRRORED_REPEAT | 和GL_REPEAT一样,但每次重复图片是镜像放置的。 |
| GL_CLAMP_TO_EDGE | 纹理坐标会被约束在0到1之间,超出的部分会重复纹理坐标的边缘,产生一种边缘被拉伸的效果。 |
| GL_CLAMP_TO_BORDER | 超出的坐标为用户指定的边缘颜色。 |
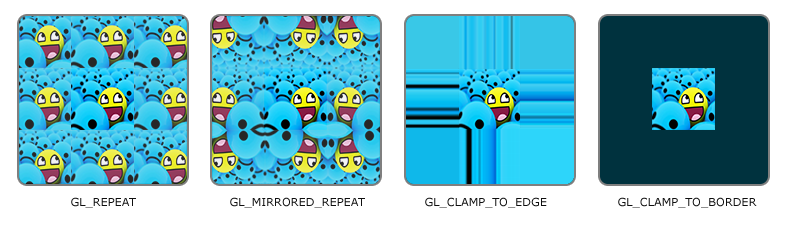
需要注意的是,该设置针对的是每个单独的坐标轴,可用glTexParamter函数进行设置
// S: x axis T: y axis
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_MIRRORED_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_MIRRORED_REPEAT);纹理过滤
坐标与像素是如何对应的?
纹理坐标不依赖于分辨率,那OpenGL是如何将纹理坐标对应到纹理像素的呢?考虑两种情况
- 物体很大,但纹理的分辨率很低,比如在500 * 500的矩形设置一个100 * 100的纹理。即一个像素如何填充到多个屏幕像素,即纹理放大(Zoom in)
- 物体很小,但纹理的分辨率很高,比如在100 * 100的矩形设置一个500 * 500的纹理。即多个像素如何映射到一个屏幕像素,即纹理缩小(Zoom out)
此时,这种场景下我们需要用到**纹理过滤 (Texture Filtering)**的选项,选择有很多,我们只讨论最经典的两种。
首先请区分纹理坐标与纹理像素
- 纹理坐标:期望绘制纹理时,指定的顶点与纹理图像的位置关系,例如(0.5, 0.5), 意义是指定顶点与纹理图像的(0.5, 0.5) (百分比)位置的色彩对应。
- 纹理像素(Texture Pixel):一张图片一个个的像素。
纹理过滤选项
经典的纹理过滤有两种方式 邻近过滤GL_NEAREST 与线性过滤GL_LINEAR
邻近过滤
OpenGL默认的过滤方式,选择中心点最接近纹理坐标的像素
线性过滤
基于纹理坐标附近的纹理像素,计算一个插值,近似出这些纹理像素之间的颜色,类似于计算一个均值或加权值,如果一个纹理像素的中心距离纹理坐标越近,那这个纹理像素的颜色对最终样本颜色对贡献越大。
对于纹理放大,通常使用glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); 来选择过滤方式。
动手实践
绘制一个非常小的圆,使其像素大概在40左右,如下所示
然后将其基于1200*1200的画布上进行绘制
当设置选项为邻近过滤与线性过滤时,我们能很清晰地看出差别
优缺点及使用场景
可以看出,GL_LINEAR的变化更平滑的感觉,过渡更自然。而GL_NEARST更有锯齿感。有些开发者更喜欢8-bit风格,所以可能会选用GL_NEARST选项
🤔 拓展一下,游戏中的抗锯齿是否跟这个选项有关呢?
理解纹理过滤的一大注意点
需要理清的是,为什么我们只指定了4个纹理图片顶点,即可渲染出整个矩形图片?
要明白,片段着色器在光栅化阶段之后,而光栅化阶段其实是将画布屏幕上的每个像素转化为UV坐标(基于三角形插值),而传到片段着色器。因此其实是有许多个点传到了片段着色器进行上色。
多级渐远纹理
以上纹理过滤我们通常处理的是大画布设置小纹理,而对于小画布设置大分辨率纹理,我们有额外的处理方案,即多级渐远纹理(Mipmap),让缩小过滤更平滑。这个词似乎在Android开发中也时常出现,经常表示一些比较小的Icon,且往往会根据大小和分辨率进行分级。
想象一下,假设我们有一个包含着上千物体的大房间,每个物体上都有纹理。有些物体会很远,但其纹理会拥有与近处物体同样高的分辨率。由于远处的物体可能只产生很少的片段,OpenGL从高分辨率纹理中为这些片段获取正确的颜色值就很困难,因为它需要对一个跨过纹理很大部分的片段只拾取一个纹理颜色。在小物体上这会产生不真实的感觉,更不用说对它们使用高分辨率纹理浪费内存的问题了。
原理:距离观察者超过一定的阈值,则OpenGL会使用不同的多级渐远纹理,选最适合物体距离的那个。
通常,我们需要设置纹理缩小的过滤方式,手动开启Mipmap过滤
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);确在通过glTexImage2D上传原始纹理后,我们还需要调用该方法来生成Mipmap级别
当然,也可以通过glTexImage2D手动创建的Mipmap(需指定level层级)
加载与使用
因为纹理的格式有很多种,可以是png、jpg等等,但最终,我们需要的是其二进制数据,因此我们可以用一个流行的图像来解决 “stb_image.h”,是一个非常流行的单头文件加载库,能加载大部分流行的文件格式。具体怎么加载就不再赘述。
给出一个典型的纹理加载与使用模板,与VBO类似,也是创建、绑定、设置、上传、清楚。需要注意的是,如果使用多个纹理,则需要逐个进行激活(默认使用一个的话不用激活)
float vertices[] = {
// ---- 位置 ---- ---- 颜色 ---- - 纹理坐标 -
0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 1.0f, 1.0f, // 右上
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, // 左下
-0.5f, 0.5f, 0.0f, 1.0f, 1.0f, 0.0f, 0.0f, 1.0f // 左上
};
int width, height, colorChannels;
unsigned char *data = stbi_load("statics/one_piece.jpeg", &width, &height, &colorChannels, 0);
GLuint texture1;
glGenTextures(1, &texture1);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture1);
// set the texture wrapping parameters
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT); // set texture wrapping to GL_REPEAT (default wrapping method)
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
// set texture filtering parameters
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
stbi_image_free(data);理解
理解清楚这里VBO中定义的顶点 & 纹理坐标与画布的关系,1.0f到底,0.5f到底对应着什么?如果改为2.0f会有什么结果?
RGB or RGBA? 图片格式带来的问题
在glTexImage2D要小心,因为其要传入图片原有的像素模式(例如RGB还是RGBA), 这在随后的采样过程中是非常重要的。
因为采样时从之前读取的字节数组中拿到数据,而RGB是3字节一组,RGBA是4字节一组,此处的设置将会影响后续的色值读取。
同时,顶点着色器获取VBO中的纹理坐标信息并最终传递给片段着色器。片段着色器中,需通过uniform显示声明sampler2D的texture参数,并调用texture方法来进行采样(最终获得的也是一个RGBA颜色值)
#version 330 core
out vec4 FragColor;
in vec3 ourColor;
in vec2 TexCoord;
uniform sampler2D ourTexture;
void main()
{
FragColor = texture(ourTexture, TexCoord);
}因其是颜色属性,所以我们可以有多种方式将其组合
比如使用mix()函数,将其与另一个纹理采样结果进行带权重的线性拟合,能得到“你中有我”的效果。
提示
可以通过一些数据技巧来实现图片竖直或水平方向的反转
FragColor = texture(ourTexture, vec2(1.0-TexCoord.x, TexCoord.y));纹理上下颠倒
实际渲染出来的纹理可能是上下颠倒的,这是因为OpenGL要求的原点是在图片的底部,而实际图片的原点通常在顶部,因此需要借助stb_image.h帮助我们在加载图像时反转y轴
stbi_set_flip_vertically_on_load(true);纹理单元
一个纹理的位置值通常称为一个纹理单元(Texture Unit),一个纹理的默认纹理单元是0,并且默认是激活的。所以之前不需要设置。如果我们要使用多个纹理单元时,在使用前,我们需要先激活,然后再进行绑定。因为激活纹理单元后,之后的绑定操作会绑定这个纹理到当前激活的纹理单元。
glActiveTexture(GL_TEXTURE0); // 在绑定纹理之前先激活纹理单元
glBindTexture(GL_TEXTURE_2D, texture);OpenGL至少保证有16个纹理单元可用。
变换
除了使用uniform变量配合时间进行位置变换,目前似乎我们都绘制的是静态的图片,如何让画面动起来呢?
能想到的除了以上的方式,可能还会想到我们可以声明在顶点缓冲区VBO中,并在渲染时重新配置缓冲区来使得移动,但这种方式太繁琐了,需要大量内存。因此该怎么实现运动地效果呢?我们可以借助一些数学运算进行
使用 矩阵 来变换 一个物体
回顾线性代数
向量的基本概念
谈到矩阵与变换,通常都与向量相关,因此在学习这部分内容钱,需要先了解一下向量的基本概念以及运算,列出可能会用到的几点
- 向量的意义、向量加减、向量长度、单位向量、向量标准化、向量的点乘与叉乘
- 空间的基,线性相关与线性无关
- 矩阵的数乘、矩阵相乘
- 矩阵的线性变化及其特性,剪切、放缩、旋转的运算原理
- 矩阵变化的顺序,几何意义
- 矩阵相乘的几何意义
- 齐次坐标及意义
这里自己有空可以再回顾一下向量点乘与叉乘的几何意义
📖 如Tutorial中所述,非常推荐3Blue1Brown的系列教学《Essence of linear algebra》,学习后对线性代数的几何意义有所理解 👍
可视化网站
对于矩阵变换的几何意义,可以借助Visualize It来可视化地理解矩阵变化后的坐标系,或者说空间
从这里开始假设你已经了解了线性代数,对向量、矩阵变换的几何意义有所理解。
实践
在OpenGL中的实际操作中,没有直接提供操作矩阵的库,要操作矩阵,实现矩阵的乘法或更高级地,进行矩阵变换(剪切、旋转等),我们需要使用到glm库
OpenGL Mathematics (GLM) is a header only C++ mathematics library for graphics software based on the OpenGL Shading Language (GLSL) specification.
🇨🇳 - OpenGL 数学 (GLM) 是一个仅有头文件的 C++ 数学库,适用于基于 OpenGL 着色语言 (GLSL) 规范的图形软件。
如上所述,glm是支持glsl语言的
因此大概的使用方式如下:
glm::mat4 trans;
trans = glm::mat4(1.0);
unsigned int loc = glGetUniformLocation(shader.ID, "transform");
glUniformMatrix4fv(loc, 1, GL_FALSE, glm::value_ptr(trans));同时需要在顶点着色器的glsl文件中进行配置 mat4 类型的 变量。
// ignore ...
uniform mat4 transform;
void main()
{
gl_Position = transform * vec4(aPos, 1.0);
}我们就可以实现在不改变原始顶点数据的情况下基于矩阵变换实现图像的变换。例如这里,我们基于 变换矩阵$ \begin{bmatrix} 1 & 1 & 0 \ 0 & 1 & 0 \ 0 & 0 & 0 \end{bmatrix} $来实现剪切效果,使得图片被对角拉伸。
理解变换所需要用到的线性知识
自己在理解变换的数学逻辑时,发现很多线性代数的知识都忘了,甚至在以前学习时忽略了,在这里列举一部分
- 理解矩阵变换与实际矩阵乘法的顺序是怎样的?
- 为什么矩阵乘法具有结合律?
- 为什么求和运算在什么情况下具有交换律?(这一点的理解也很重要,尤其在于理解上一点
坐标系统
物体的顶点最终转化为屏幕坐标前还会经历多个坐标系统的变化。总的来说有五个不同的坐标系统
- 局部空间 Local Space
- 世界空间 World Space
- 观察空间 View Space/Eye Space
- 裁剪空间 Clip Space
- 屏幕空间 Screen Space
那每个空间都有自己的坐标系,将坐标从一个坐标系变化到另一个坐标系,听起来是不是很熟悉?回顾下线性代数中是如何变幻坐标系的?我们需要用到变换矩阵,如果对这部分还不熟悉,请先回顾下线性代数矩阵的几何意义~
在此,我们将用到模型(Model)、观察(View)、投影(Projection)三个矩阵
我们的顶点坐标起始于局部空间,坐标被称为局部坐标,此后会变为世界坐标,观察坐标,裁剪坐标以及最终的屏幕坐标。
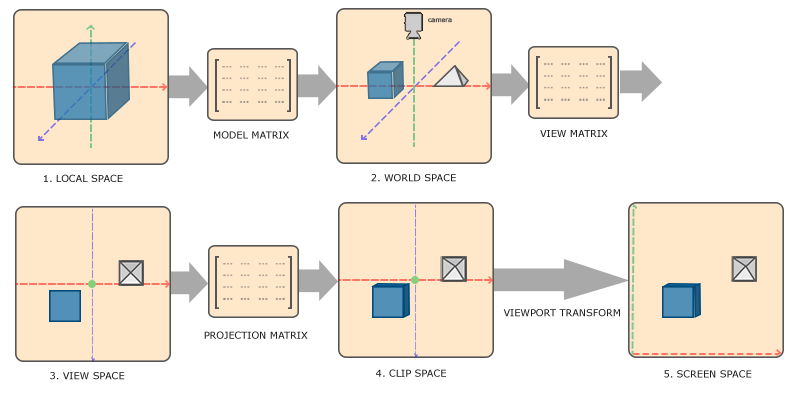
先从宏观上来了解下过程:
- 局部坐标是相对于局部原地那的坐标,也即物体的起始坐标。
- 物体和其他物体基于全局原点进行摆放
- 世界坐标再转化为观察空间坐标,每个坐标都是从摄像机角度进行观察的
- 观察坐标投影到裁剪坐标,被处理到[-1.0, 1.0]的范围内,并判断哪些顶点会出现在屏幕上
- 基于视口变化(Viewport Transform)过程裁剪坐标转化为屏幕坐标,将[-1.0, 1.0]的坐标转化到由
glViewport函数所定义的坐标范围内,并将最终得到的坐标传到光栅器,转化为片段。
类似于有如下的公式
对具体某个空间的概念及原理不太清楚也不要着急,后面会慢慢学到,这里有个大概了解即可。
右手坐标系 Right-Handed System
需要注意,OpenGL采用的是右手坐标系(DirectX采用左手坐标系),特性可以理解为z轴正方向指向屏幕前的自己。
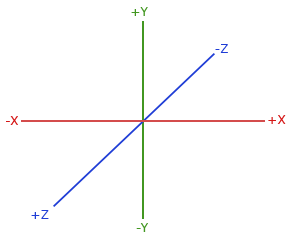
3D
我们现在知道了如何将3D坐标转化为2D坐标,有了以上的知识储备后,现在我们终于可以踏足3D领域啦!
第一个3D物体
现在我们来开始构建第一个3D物体,一个正方体!
首先让我们理清楚正方体的基本特性:我们知道,正方体一共有6个面,每个面由4个顶点构成1个正方形,1个正方形由2个三角形构成,每个三角形3个顶点,因此如果不采用EBO的索引指示方式,我们需要在VAO中声明 6 * 2 * 3 = 36 个顶点(包含重复的顶点),并指明每个顶点对应的纹理坐标。
对于其中一个面,我们有类似如下的定义
float vertices[] = {
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
0.5f, -0.5f, -0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
// ..
}接下来,我们要开始构思如何设计坐标变换了,根据之前坐标转换的过程,我们将其适配到Vertex Shader中,需要注意矩阵相乘的顺序
out vec3 color;
out vec2 texCoord;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
color = inputColor;
texCoord = inputTexCoord;
}那如何来设置这些值呢?
首先从Model、View、Projection三方面明确下我们的需求:
- 世界空间:我们希望让这个正方体旋转一下(否则若从正面观测那我们也不知道它是一个正方体呀)
- 观察空间:世界那么大,我们希望能看得更广一些,不要仅局限于眼前的目标。
- 投影空间:我们希望看地更真实一点,当物体离我们较远时,越远的部分越小
glm::mat4 model = glm::mat4(1.0f);
// 设置物体在世界坐标位置偏移,此处不偏移
model = glm::translate(model, glm::vec3(0.0f, 0.0f, 0.0f));
// 设置物体旋转角度,绕x轴逆时针旋转20度
float angle = 20.0f;
model = glm::rotate(model, glm::radians(angle), glm::vec3(1.0, 0.0, 0.0));
// 设置物体观察坐标
glm::mat4 view = glm::mat4(1.0f);
view = glm::translate(view, glm::vec3(0.0f, 0.0f, -2.0f));
// 设置透视坐标,暂时不深究代码
glm::mat4 projection = glm::mat4(1.0f);
projection = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f);OpenGL默认View视角
OpenGL默认观察视角是从原点到z轴负方向,因此要实现看得更远,我们可以沿z轴负方向移动物体
旋转角度问题
关于这里,如何来判断绕一个轴旋转的方向?这其实也属于数学问题,针对OpenGL采用的右手坐标系,请使用 右手法则, 即右手竖起大拇指水平放置, 大拇指朝向与旋转轴方向保持一致,其余四指所指方向即为旋转的正方形,默认正方形是逆时针。
关于这里的原理与向量的叉积有关,这里暂时不深究
当然,设置完后,我们还需要将这些坐标上传到OpenGL中
int locModel = glGetUniformLocation(shader.ID, "model");
glUniformMatrix4fv(locModel, 1, GL_FALSE, glm::value_ptr(model));
// ...于是我们就得到了第一个看起来3D的正方体
现在我们尝试通过动态设置model参数,让正方体旋转,动起来?但很快我们会发现一个问题,看起来似乎怪怪的,头晕晕的 🤕
Z缓冲
似乎以上的物体中看起来让人头晕?因为部分本应该在后面的面实际渲染时却来到了画面顶部。
OpenGL存储它的所有深度信息在一个Z缓冲中(Z-Buffer),也称为深度缓冲(Depth Buffer),深度值存储在每个片段中,作为片段的z值。当片段要输出该部分颜色时,其会进行深度测试(Depth Testing):OpenGL会将其深度值与Z缓冲进行比较,如果当前当前片段在其他片段之后,则它将被丢弃,否则将会覆盖。
而OpenGL默认关闭了深度测试,我们必须先手动启用。
glEnable(GL_DEPTH_TEST);同时,因为我们使用了深度测试,我们需要在每次渲染迭代前清楚深度缓冲(否则前一帧的深度信息仍然保存在缓冲中)。
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)如下设置后,我们便能得到一个看起来正常旋转的立方体!
同样我们可以设置多个正方体,并通过设置旋转角度来控制每个正方体的旋转。看看是不是更加立体了?
观察空间
Camera
OpenGL本身没有摄像机的概念,但我们可以通过把场景中的所有物体往相反方向移动的方式来模拟出摄像机,产生出一种是观测者在移动而不是物体在移动的错觉。
首先,对于摄像机,或者观测者而言,其视界内有着自己的一套坐标系(比如这个人离我多远,离我多高)。因此我们讨论如何以观测者视角展示物体也即如何把一个物体从一个坐标系转化到观测者的坐标系,这点 是非常重要的。
有了这个理解后,似乎就变得简单了,因为借助矩阵乘法,我们能轻易地进行坐标变换。
但不妨再来看看OpenGL中是如何操作的。
注
注:后续可能会不断观测者、摄像机的概念,它们都表达相同的意思。
确定观测者位置
首先我们需要确定观测者的位置,假设它在(0, 1, 1)这一个点,我们想站在近处俯瞰一个物体,注意不是负值,因为这是对观察者而言。
确定观测方向
观测者位置确定了,但这个观测者要往哪个地方看呢?人的眼球可看不了360度,可以往上看可以往下看,到底看哪个方向呢?因此我们需要确定观测方向。
这里假设让摄像机指向原点,因此摄像机观测方向就是从(0, 1, 1) 到(0, 0, 0)。用场景原点向量减去摄像机位置向量的结果就是摄像机的指向向量。由于我们知道摄像机指向z轴负方向,但我们希望方向向量(Direction Vector)指向摄像机的z轴正方向。如果我们交换相减的顺序,我们就会获得一个指向摄像机正z轴方向的向量
警告
方向向量(Direction Vector)并不是最好的名字,因为它实际上指向从它到目标向量的相反方向
确定剩余轴线方向
现在我们计算出了摄像机变换后的z轴正方向,按照坐标系的右手法则,我们现在找到了中指方向,我们还需要计算出另外两个轴的方向。
一种方式是我们先定义一个上向量,将其与方向向量进行叉乘,获得的向量自然垂直于这两个向量决定的平面,即我们找到了大拇指的指向,即x轴正方向向量。
然后再由这两个确定的轴线的方向进行叉乘,获得食指的方向,即y轴方向。
上方向的运算
这里上方向的定义以及叉乘的运用是否有点像高中数学中几何题法向量部分的运算?
一般来说,摄像机的 Up 向量应该和视线(View Direction)正交,并且通常与世界坐标的 +Y 轴尽可能对齐。
常见的默认上方向是世界坐标系的 Y 轴(0,1,0),但我们需要确保它与 view_dir 不平行,并且可以构造一个正交的坐标系
如何确保与 view_dir 不平行? 使用向量的点积,不为0即代表不平行
最终,将这三个向量进行组合,我们便得到了摄像机坐标系的变换矩阵。
当然也可以使用glm::lookAt函数一步到位,此处对API不做赘述。
给出两种方式的代码实现
1. 逐步实现
// 1. 声明摄像机位置
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f);
// 2. 确定摄像机z轴方向
// 2.1. 声明摄像机观测点之一以确定方向
glm::vec3 cameraTarget = glm::vec3(0.0f, 0.0f, 0.0f);
// 2.2. 确定其z轴指向,并进行归一化
glm::vec3 cameraDirection = glm::normalize(cameraPos - cameraTarget);
// 3. 确定右方向即x轴,基于向量叉乘
glm::vec3 up = glm::vec3(0.0f, 1.0f, 0.0f);
glm::vec3 cameraRight = glm::normalize(glm::cross(up, cameraDirection));
// 3. 确定上方向即y轴,基于向量叉乘
glm::vec3 cameraUp = glm::cross(cameraDirection, cameraRight);
// 4. 组合三个方向的向量
glm::mat3 matrix(...)2. lookAt
// 原点位置 | 目标指向 | 临时的上方向向量
glm::mat4 view;
view = glm::lookAt(glm::vec3(0.0f, 0.0f, 3.0f),
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(0.0f, 1.0f, 0.0f));并按照之前的坐标变换过程,将该View矩阵应用到坐标变换中,最终我们就能从摄像机视角观察物体 👀
可水平或垂直移动的Camera
大部分场景下,视角是可以移动的,此时因此我们需要动态地来改变Camera位置,想想该怎么做呢?比如让观察者更靠近物体(不过视线角度仍然与之前保持一致,之前是平视那现在也是平视)。那就应该在原来的摄像机坐标的基础上,使摄像机沿着摄像机指向方向(即摄像机坐标系z轴的负方向移动)。
因此我们可以进行如下定义
// 摄像机原始位置
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f);
// 摄像机指向
glm::vec3 cameraFront = glm::vec3(0.0f, 0.0f, -1.0f);
// 摄像机临时上方向
glm::vec3 cameraUp = glm::vec3(0.0f, 1.0f, 0.0f);
// 摄像机移动速度(与每帧更新间隔相关)
float cameraSpeed = 2.5f * deltaTime;
view = glm::lookAt(cameraPos, cameraPos + cameraFront, cameraUp);需要想清楚的是,为什么lookAt中第二个参数,观测点位置变为cameraPos + cameraFront?这是因为按照这种方式,我们能保证无论怎么移动,摄像机都会组注视目标方向。
因此我们可以适当地增大其位置,当然需要配合输入指令,要在glfw中注册输入监听函数,并进行按键判断。
if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS)
{
cameraPos += cameraSpeed * cameraFront;
}再渲染循环中,重新构造View矩阵并传值即可。
如果想左右移动,该怎么办呢?
类似地,如果是向右移动,则我们需要沿着原摄像机x轴方向增大其值,这里,因为我们并没有显示地声明摄像机x方向向量,因此我们用叉乘并基于摄像机方向向量以及上向量
if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS)
{
cameraPos += glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed;
}还需要将叉积的向量标准化以得到方向向量哟。
向量叉积的右手定则
自己在理解这里的时候总是认为应该是方向向量的负方向叉乘上方向才是正确的右方向,但这里其实是忘记了右手定则
- 拇指指向 A 的方向(cameraFront)。
- 食指指向 B 的方向(cameraUp)。
- 中指指向叉积 A × B 的方向(cameraRight)。
抽时间理解下叉积的几何意义。
可缩放的Camera
作为一台现代摄像机,肯定是有缩放的功能的,首先理解下缩放,即就像用望远镜一样,能够看得更远(但看得更窄),或者看的更广(但只能看得更近)。
此时就用到了我们投影相关的部分。
glm::mat4 projection = glm::mat4(1.0f);
projection = glm::perspective(glm::radians(fov), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f);
int locProject = glGetUniformLocation(shader.ID, "projection");glm::perspective 是 GLM 提供的**透视投影(Perspective Projection)矩阵生成函数,用于将 3D 场景投影到 2D 视图中,模拟现实世界中的透视效果(近大远小)。在 3D 图形渲染中,透视投影用于将视锥体(frustum)**内的物体投影到屏幕上,并进行透视变换。
对于其参数,我们有
| 参数 | 作用 | 说明 |
|---|---|---|
fovy | 视场角(Field of View, FOV) | 指定纵向视场角,以弧度为单位(用 glm::radians() 转换)。 |
aspect | 纵横比(Aspect Ratio) | 宽度 / 高度,决定视野的拉伸比例,通常为 屏幕宽 / 屏幕高。 |
zNear | 近裁剪平面(Near Plane) | 观察范围最近的可见距离,必须为正值。 |
zFar | 远裁剪平面(Far Plane) | 观察范围最远的可见距离,必须为正值。 |
这里我们需要重点了解下视锥体与fov,首先需要知道视锥体概念的几何模型,则fovy的概念就不是很陌生了

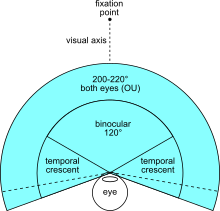
常见的fov如下
| 应用场景 | 典型 fovy 角度 | 说明 |
|---|---|---|
| 人眼视角 | 45° - 60° | 适用于大多数 3D 游戏、FPS(第一人称射击)、VR 等,接近人眼真实视角。 |
| 标准 3D 渲染 | 45° | 经典 FOV 值,适用于大多数 3D 应用和游戏,如第三人称视角、建筑可视化。 |
| 广角镜头(Wide FOV) | 75° - 90° | 适用于赛车游戏、第三人称冒险游戏,提供更广阔的视野,但可能会产生鱼眼畸变。 |
| 超广角(Ultra-Wide) | 100° - 120° | 适用于 VR(虚拟现实)、多屏幕显示(如 32:9 画面),会有明显的透视变形。 |
相关信息
关于视锥体的几何知识,可以抽空再了解下~
关于实际应用,我们只需要注册滑轮滚动监听函数,根据滑轮移动来动态地设置fov值即可,此处不过多赘述代码
可旋转的摄像机
我们往往还希望以不同的姿势来看物体,比如俯视或仰视,又或者是侧着看。因此这里我们再引入欧拉角的概念
欧拉角(Euler Angle)是可以表示3D空间中任何旋转的3个值,由莱昂哈德·欧拉(Leonhard Euler)在18世纪提出。一共有3种欧拉角:俯仰角(Pitch)、偏航角(Yaw)和滚转角(Roll)
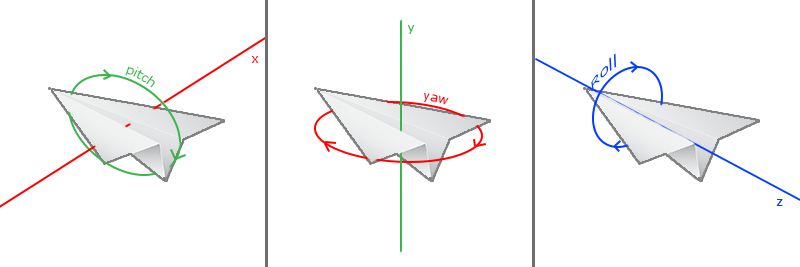
需要理解的是:
- 俯仰旋转,即通过旋转x轴进行
- 偏航旋转,即通过旋转y轴进行
- 滚转旋转,即通过旋转z轴进行,由于这里我们“不开战斗机”,不需要做华丽的旋转操作,因此暂时不需要这个属性~
那么我们的重点就在于:摄像机进行某种旋转操作后,变换后的坐标系是什么,对应的变换矩阵是什么?
这里我建议读者在理解时自己动手画图,画出对应的旋转角度并进行转化,需要与球坐标知识结合,推导过程就不列举了,这里给出变换矩阵
(这里r0代表球坐标下变换后的点到原点距离)
注意点
我在理解这部分时,最初遇到了些阻碍,比如我一直认为yaw角逆时针旋转应该是从x轴正方向到z轴负方向
需要注意以下的点,并仔细对照Tutorial中的二维图片
- yaw与pitch角是如何定义的?
- 明白摄像机最初方向向量是z轴负方向,但默认yaw为0时,指向的是x轴正方向,因此我们要做一个修正,进行适当旋转
具体而言怎么做这里也不再赘述,实际使用时还需要注意“万向死锁”问题,限制角度在90度以内
光照
颜色
我们通常使用RGB来表示一个颜色
现实生活中,我们看到某一物体的颜色并不是这个物体真正拥有的颜色,而是它所反射的饭颜色,即不能被物体所吸收的颜色。
通常我们将光源的颜色与物体颜色值相乘,就得到这个物体所反射的颜色(想想坐标变换与xyz轴,是不是有点相似?)
OpenGL实践中该怎么做呢?是不是跟片段着色器有关?
我们可以定义一个物体的颜色,并传递到片段着色器中,对每个片段都使用相同的颜色,于是便得到了一个上色的立方体
可以再定一个光源,并为光源上色,最终就有类似的效果
复习
这里可以再回顾一下VBO VAO的绑定关系,一个VBO如何对应两个VAO以及渲染时VAO绑定与绘制顺序~
问题清单
OpenGL与OpenCV有什么区别?
- OpenGL: 主要用于图形渲染,直接操作GPU
- OpenCV: 专注于图像处理和计算机视觉,用于图像分析、对象识别、视频处理