
Kotlin-Coroutines-协程与线程内存实验
Kotlin-Coroutines-协程与线程内存实验
都说Kotlin的协程比Java线程轻量,因此我们来看看两者到底有什么区别
首先要明确的一点是,Kotlin协程也是基于线程的,这毋庸置疑。因此需要先消除两者是独立个体的想法,协程运载在线程之上
Java线程
::: important首先明白栈空间是什么?
在 JVM 里,每条 Java 线程都会拥有一块独立的 Java 虚拟机栈(Java Stack)。它按“栈帧(Stack Frame)”的形式保存一次方法调用的全部运行时信息. 包括局部变量饮用、操作数栈、方法返回地址。需要注意这与我们所说的堆和大部分gc场景是不同的。比如不正常的递归很有可能引起StackOverFlow这个问题,其实就是栈空间溢出。
:::
因此我们的思路是:java启动非常多个(1000个)线程,设置每个线程的最大默认栈空间(2MB),并且希望尽可能地占满这个栈空间,在任务管理器等一些监控app中来查看情况是否属实
因此先构建我们的Java代码
fun main() {
println(ProcessHandle.current().pid())
for (i in 0 until 1000) {
val thread= Thread({
deepCall(17000)
})
thread.start()
}
// 保持程序不退出
Thread.sleep(1000000);
}
fun deepCall(depth: Int) {
if (depth == 0) {
println(Thread.currentThread().name + " Sleep")
Thread.sleep(1000000)
} else {
deepCall(depth - 1)
}
}并在IDEA中启动时设置VM Option: -Xss2m -Xint
主要逻辑:如上所述,我们启动了1000个线程,并设置了这些线程的最大栈空间为2MB,随后我们尝试在每个线程中递归地调用一个方法,一直到StackOverFlow**之前。**以此来增大每个线程所占用的栈空间。
理想情况: 整个进程的线程数量在1000以上,并且内存占用量在1.9GB左右
$\frac{1000_{thread_numbers}\ * \ 2 * 1024kb}{1024 * 1024} GB \approx 1.9GB $
实际结果:可以看到,最终与理想情况基本一致。
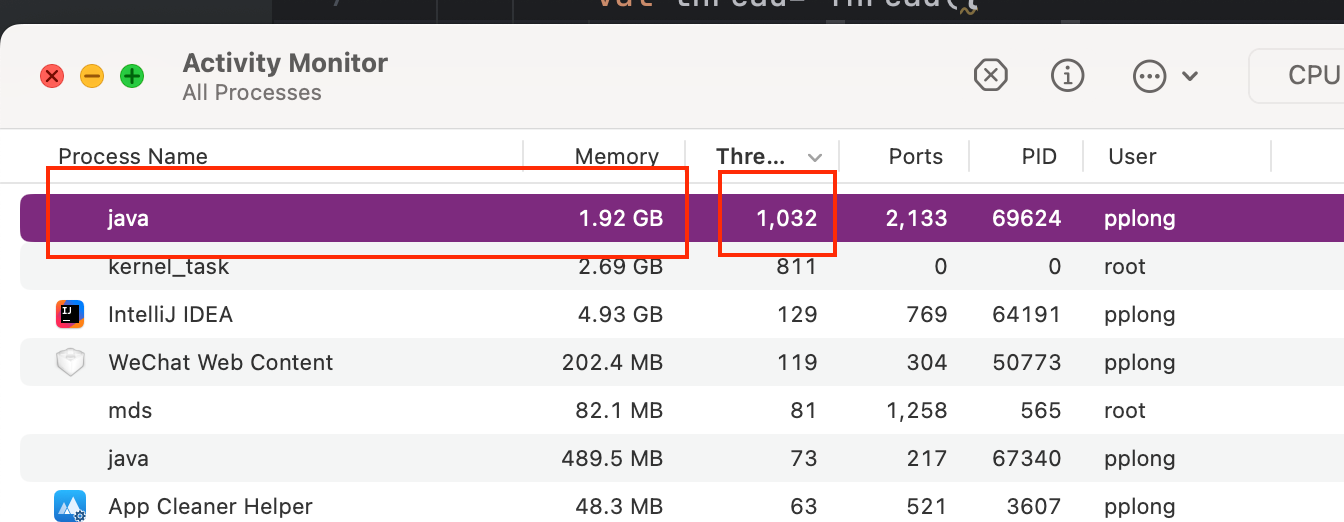
好,但整个测试过程并不是那么一番风顺,因此现在来回顾一些问题,也是我在实践中遇到的。
栈空间分配问题
一些问题:
为什么必须要递归地调用?栈空间为什么在设置后就不是一个固定值而是动态变化的。
-Xss2m设置了栈空间最大为2MB后,栈空间不是立即分配死了,而是随后随着实际调用过程逐渐增大。
如果在线程中只打印log然后sleep,则线程的栈空间是多少?
理解预留和占用两个概念
回顾下物理地址、虚拟地址、地址映射、页表等OS概念
- 预留 Reserve: JVM在创建线程时,向OS申请一块连续地址 2MB,但此时不分配任何物理页,只是在页表中登记“这段地址属于我”。
- 占用 Commit: 线程栈指针每向下走到一页的保护边界,第一次写入时会出发缺页异常,OS才真正分配一页物理内存并映射到这段虚拟地址。
因此,保留到是地址,而真正使用时才占物理内存
因此,我们在一些进程监控app中比如top命令以及mac中的Activity Monitor监控时,发现其实在没有递归调用时,占用的内存很少,很有可能就是因为它们只统计已提交的物理页,而无法看到纯预留地址空间。
因此,我们若不进行递归调用来占满栈空间,则实际栈空间的占用量非常小,这也是为什么在最开始我没有递归调用,只在线程中print了一句话时看到只占用十几MB的空间的原因了。
栈溢出问题
最开始我的调用层设置的非常大,也就是一定会造成StackOverFlow,但其实最后我看该进程的空间占用,其实并没有很大。
这是为什么?明明都已经溢出了,为什么还很小?
因为线程产生Error/Exception后,若未捕获异常,则会直接关闭。也就是进程中的线程数量会减少,因此导致了进程的占用量也减少了。
同时,从这个情景,也能再次复习到,线程崩溃并不一定会导致进程崩溃。
Xint问题
- 为什么要加Xint这条options呢?
有问题的源头是我最开始启动进程后,期待的进程内存占用量没有达标(预估1.9GB但实际只有1.3GB),同时查看Log,发现仅有一小部分线程(并且是出现在运行之初)出现了StackOverFlow,而另一些线程则被正常地阻塞了,也就是顺利地调用完了整条递归链,并阻塞在了最后一层。
因此就会让我想到,也就是最开始运行的线程因为一些原因产生了StackOverFlow,但后续的一些线程都没有,所以从内存占用上:
- 一些线程抛出了StackOverFlow Error,导致线程断掉,总线程数减少,因此占用内存会减少
- 另一些线程没有抛出StackOverFlow,说明其内部的栈空间占用量还远不及阈值,因此占用的内存也没有接近预计值。
这一点自己思考时没有想到,这里直接给出答案
产生这个现象的根本原因是: “每个线程真正消耗的栈帧大小并不完全相同”。
概括地来说,就是在递归调用中,早期的栈帧更大一些。
来回顾下我们JVM中的不同编译方式
| 解释执行 Interpretor | JIT编译 Just-In-Time | AOT预编译 Ahead-Of-Time |
|---|---|---|
| 运行每条字节码时,边解释边执行 | 程序运行一段时间后,热点方法才被编译 | 构建阶段已经将字节码编译为机器代码 |
看到这里,基本有了个大概理解。
而默认地,在标准的JVM中,默认采用 解释执行 + JIT编译 的混合模式。
因此,在先启动、运行递归方法的线程中,整个VM是采用的解释模式,解释模式下每一帧需要保存完整的局部变量表、常量池索引、字节码PC等,而在运行一段时间后,VM启用JIT编译模式一旦该方法被JIT编译后就转化为编译帧。只需要保留必要的寄存器溢出区以及调试信息。解释器针通常比编译帧大2-5倍。
所以为了解决“仅有一小部分线程(并且是出现在运行之初)出现了StackOverFlow”这个问题,即让所有线程要么栈空间都溢出,要么都不溢出,因此我们这里修改编译方式为解释执行,所以最终使用到了 -Xint命令
所以,现在我们可以给出结论
结论
所说的Java线程占用空间大并不完全正确,JVM中默认指定的线程栈空间在(256k-4MB),并不是一创建线程就立马有1-2MB的物理空间被占用。而是随着后续的调用过程不断变化的。